")
Large Language Models (LLMs) have transformed the AI landscape, driving innovation in text generation, question-answering, and conversational AI. However, as these models become more sophisticated, evaluating their performance requires the use of specialized metrics that capture their nuances and capabilities. Below, we delve into the evolution of LLM metrics, their applications across tasks, and how models have varied in their performance over time.
Evolution of LLM Metrics
Metrics for evaluating LLMs have expanded to match the growing complexity of tasks they perform. Foundational measures such as perplexity and accuracy remain crucial, but their limitations in capturing human-like qualities necessitate supplemental metrics. BLEU, ROUGE, and F1, while long-standing metrics in natural language processing, have been joined by human evaluations and task-specific measures like Exact Match and Dialogue Coherence Scores to address the broader capabilities of LLMs.
Platforms like Hugging Face have played a pivotal role in democratizing access to LLMs and associated benchmarks. The trending models on Hugging Face, such as OpenAI’s GPT-series, Meta’s LLaMA, and other advanced offerings like Bloom and Falcon, highlight how various metrics reflect a spectrum of performance attributes. Each model’s alignment with metrics provides insights into strengths, such as fluency in text generation, factual accuracy in QA, or contextual coherence in dialogues.
At SB Solutions, we are leveraging the potential of LLMs to solve FinTech problems, utilizing a dedicated team of scientists. Sandeep, our CTO, highlights that Small Language Models (SLMs) are set to dominate enterprise applications due to their cost-effectiveness, privacy-preserving capabilities, and adaptability for domain-specific tasks and operations. This shift aligns with industry trends emphasizing the need for secure and efficient AI systems tailored to organizational requirements.
1. Text Completion/Generation
Text generation remains one of the cornerstone applications of LLMs, enabling use cases such as creative writing, code generation, and content creation. Evaluating the quality and coherence of generated text involves the following metrics:
Perplexity

Where
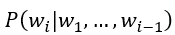
is the probability of the i-th word given the previous words. Lower perplexity indicates better prediction accuracy, but its reliability reduces for creative text generation. Note: Formula can take natural log or log to base 2.
BLEU
BLEU calculates n-gram overlap between the generated text and reference text, providing a measure of fluency and accuracy:
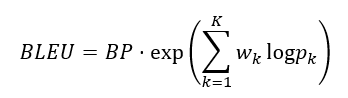
Where: – BP is the brevity penalty. – Wk is the weight for each n-gram precision. – pk is the precision for k-grams.
Human Evaluation
While subjective, human evaluation remains indispensable for assessing attributes like coherence, creativity, and relevance. For instance, Meta’s LLaMA-2 has shown to perform comparably to GPT-4 in creative writing tasks when judged by human evaluators.
2. Question Answering (QA)
LLMs excel at extracting and synthesizing information to answer queries. In QA tasks, precision and recall are paramount, and these metrics are the most commonly used:
Exact Match (EM)
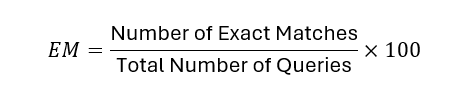
F1 Score

Where:
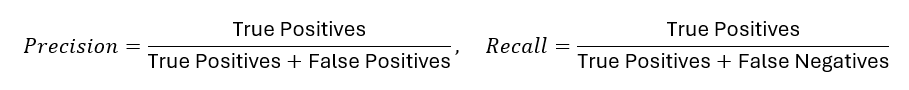
Accuracy@K

3. Dialogue/Chatbots
Conversational AI applications such as chatbots and virtual assistants rely on LLMs to provide context-aware and engaging interactions. Metrics for evaluating these systems include:
- Dialogue Coherence Score: Evaluates whether a response aligns contextually with prior conversation turns.
- Turn-Level BLEU: Measures n-gram overlap for individual conversational turns.
- Engagement Metrics: Gauges relevance and helpfulness based on user feedback.
Emerging Metrics for LLM Evaluation
As LLM capabilities expand, new metrics are emerging to address areas such as safety, fairness, and multimodal capabilities:
- CLIPScore: Evaluates text-image alignment.
- TOXICITY Score: Ensures content safety.
- Calibration Metrics: Measures prediction confidence.
Why Metrics Matter
Combining multiple metrics provides a holistic view of performance, balancing fluency, coherence, and creativity. By leveraging diverse metrics, researchers can drive responsible innovation.




0 Comments